Retrofit 통신 과정에서 Exception을 구분하여 에러 이유에 따른 예외처리를 구분하였다.
IOException ( 네트워크 통신 문제 )
HttpException ( 통신 결과 응답 코드 오류 -> 404 Not Found , 500 Internal Server Error 등...)
등을 구분하여 표현할 수 있었으나, HttpException의 경우는 따로 구분하지 않았다.
우선 필요한 응답유형을 구분한다. 현재 예시로 든 코드는 로그인 / 닉네임 변경 등의 결과를 반환하는 코드로 모두 성공 / 실패만 반환하면 되기 때문에 모든 응답에서 필요로 하는 success, code를 포함하여 부가적인 message만 받아오도록 SuccessResponseDomain을 지정해줬다.
이후 repository 단에서 서버와의 응답 결과를 받아와 Error 유형에 따라 SuccessResponseDomain에 코드를 담아 ViewModel 의 LiveData로 넘긴다.
ViewModel단에서는 단순히 UI단에서 요청한 도메인의 타입에 따라 repository 단에서 역할을 수행하고, 반환 결과를 response 라이브 데이터에 담기만 하면 된다.
response livedata의 observer 의 일부 코드
이후 UI단인 Activity에서는 livedata에 observer를 정의, 등록하여 response 타입을 통해 요청 유형을 구분하고, success / code를 구분하여 UI 단에서 적절한 처리를 할 수 있다.
해당 코드는 편의를 위해 하드코딩하였다.
추가적으로 패스워드 전송 시에는 패스워드가 통신에서 평문으로 전송되는 것을 지양해야 하기에 sha256을 적용하여 해쉬된 값을 전송할 수 있도록 구현하였다.
근데 다른 Repository에서 같은 형식의 데이터 모델을 적용시켜보려고 하자 문제가 생겼다.
각각의 UseCase별로 Repository를 생성하였는데 각 UseCase에서 필요로 하는 데이터 모델은 다른데 Service단에서 제공하는 데이터 모델은 바뀌지 않는다는 점이다.
즉, Service단에서 특정 유저 정보를 가져오는 데이터의 반환값을 LoginRequestDTO로 가져오게 되면 다른 Repository에서는 그 데이터의 사용이 힘들다는 점이다. Domain 계층의 필요성을 직접 깨달을 수 있었다.
해결 방안
Service단에서 제공하는 각각의 트랜잭션에 대한 반환값과 요구값을 DTO로 정해두고, Domain단에서는 각 UseCase별로 필요한 데이터 형식을 수립해놓을 것이다. Repository(Data단) 에서 Service에 접근할 때 (DTO -> Domain) 으로 형식을 반환하여 ViewModel / Fragment (UI단)으로 넘기면 해당 Domain 형식을 가지고 Ui에 결과값을 반환하는 것이다.
이전 방식은 ViewModel 단에서 추가적인 디캡슐화/캡슐화를 진행하여 로직을 구분할 수 있을 것이라 생각했는데
결국 service 단에서 해당 로직을 구분하면 될 것으로 판단되어 굳이 viewModel 단에 추가적인 데이터모델을 수립할 필요는 없을 것 같다.
예를 들어 포스트, 댓글, 유저의 id값을 통해 삭제를 진행할 수 있는 api가 각각 따로 존재한다면
DomainModel에는 enum값을 포스트 / 댓글 / 유저를 구분하여 repository로 넘겨주면
repository단에서 각각을 구분하여 service에 요청할 수 있을 것이다.
가장 중요한 것은 각각의 UseCase별로 필요한 요청을 명확히 구분하는 것이라 생각된다.
파이어베이스 위주가 아닌 제대로된 백엔드와의 협업은 처음이라 기본적인 서버 통신 과정에 대해서도 많은 어려움이 있었는데, 특히 단순히 UI를 표시하기 위해 필요했던 데이터들과 서버에 통신을 위한 모델을 어떻게 연결해야할지에 많은 어려움이 있었다.
기존에 진행하였던 부분에서는 서버와의 통신을 배제한 상태에서 진행하다보니 UseCase별 필요한 요청과 응답 부분을 생각하지 않고 진행했던 것이 현재 시점에서 많은 수정을 필요로 하는 어려움을 가져다 준 게 아닐까 되돌아본다.
api가 다 나와있는 시점에서 개발에 들어갔다면 api별로 dto형식을 지정해 변환과정을 거칠 필요가 없이 바로 Repository단에서 필요한 데이터만 올려 보내면 될 일이지만, 명확한 반환값이 정해지지 않은 현재 시점에서 개발 일정에 맞추기 위해 다른 부분들을 마무리 해야하는 점이 많은 어려움이 있었다.
아직 진행되지 않은 부분을 완료되었다고 가정한 interface를 사용하여 이후 개발이 완료된 후에는 해당 부분만 채워두면 동작이 되도록 진행하려고 많이 노력하였고, 해당 과정에서 많은 배움을 얻을 수 있었다.
현재 프로젝트를 진행하면서 PM 역할의 중요성과 필요성을 몸소 느끼고 있다. 개발 일정을 관리하는 데 있어서 프로젝트 범위가 커지다 보니 전체 일정의 진행도를 파악하기가 너무 힘들었고,설계 과정이 부족했던 탓인지 개발 도중 누락된 개발사항이 계속해서 발견되고 있따.
프로젝트를 열심히 해도 영 진행되지 않는 모습에 답답하기도 하고 스트레스를 많이 받았지만, 최대한 Git Issue를 통해 각 프래그먼트 별로 필요한 부분을 적고 진행도를 체크함으로써 일정 관리 문제를 해결하기 위해 노력하고 있다.
Fragment에서는 각각의 요청 (로그인 / 회원가입 / 아이디 찾기 / 비밀번호 찾기)에 대해 각각의 DTO 를 사용하여
다음과 같이 ViewModel에 UserRequest 클래스로 요청한다.
loginViewModel.request(
UserRequest.Login(
LoginRequestDTO(
email = binding.username.text.toString(),
password = binding.password.text.toString()
)
)
)
/**
/* 현재 코드는 각 상황별로 직접 UserRequest(UserRequestDTO())로 요청하도록 되어있지만
/* 서버에 요청하는 코드를 UserRequestDTO 형식을 받는 함수로 따로 만들어
/* 해당 함수에서 UserRequestDTO의 형식을 구분하여 UserResponse에 담아 viewModel에 요청하는 역할을 수행하도록 하여
/* 요청하는 부분에서는 단순히 해당 코드를 각각의 DTO에 담아서 요청할 수 있도록 만든다면 가독성측면과 직관성을 보완 할 수 있을 것 같다.
**/
형식을 통해 ViewModel에게 데이터를 요청하고
class LoginActivity{
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
loginViewModel.response.observe(this, ::responseObserver )
}
private fun responseObserver(response : UserResponse){
if( loading.isShowing )
loading.dismissWithAnimation()
when(response){
is UserResponse.Login ->{
val dto = response.dto
if(dto.success){
//로그인 성공 시 결과값 표시
}
}
is UserResponse.FindIdPw ->{
val dto = response.dto
if(dto.success) {
//아이디&비밀번호 찾기 성공 시 결과값 표시
}
}
is UserResponse.Register ->{
val dto = response.dto
if(dto.success) {
//회원가입 성공 시 결과값 표시
}
}
}
}
}
ViewModel에서는 reqeust함수로 들어오는 UserRequest의 타입에 따른 요청을
repository에 UserRequestDTO 형식을 사용하여 전송한다.
UserRequestDTO형식을 사용하기 때문에 dto = requestType.dto로 미리 정의하여
_resposne.value = repository.해당함수(dto)와 같이 코드를 통일성있고 간결하게 작성할 수 있었다.
class LoginViewModel : ViewModel() {
val _response = MutableLiveData<UserResponse>()
val response : LiveData<UserResponse> = _response
val request : (UserRequest) -> Unit
init {
request = { requestType ->
val dto = requestType.dto
viewModelScope.launch {
when(requestType){
//로그인
is UserRequest.Login -> {
if ((isUserNameValid(requestType.dto.email) && isPasswordValid(requestType.dto.password))) {
_response.value = repository.login(dto)
}
}
//회원가입
is UserRequest.Register -> {
_response.value = repository.register(dto)
}
//아이디찾기
is UserRequest.FindPW -> {
_response.value = repository.findID(dto)
};
//비밀번호찾기
is UserRequest.FindID -> {
_response.value = repository.findPW(dto)
};
}
}
}
}
}
sealed class UserRequest() {
abstract val dto: UserRequestDTO
data class Login(override val dto : LoginRequestDTO) : UserRequest()
data class FindPW(override val dto : FindPwRequestDTO) : UserRequest()
data class FindID(override val dto : FindIdRequestDTO) : UserRequest()
data class Register(override val dto : RegisterRequestDTO) : UserRequest()
}
sealed class UserResponse{
abstract val dto : UserResponseDTO
data class Login(override val dto : LoginResponseDTO) : UserResponse()
data class FindIdPw(override val dto : FindResponseDTO) : UserResponse()
data class Register(override val dto : SuccessResponse) : UserResponse()
}
다음은 UI 처리 부분이다. Activity는 onCreate에서 response LiveData를 observing하게 한다.
해당 observer에서는 response의 타입을 기준으로 UI에 반영하는 부분만 처리하면 된다.
fun UserRepository() : UserRepository = UserRepositoryImpl()
interface UserRepository {
suspend fun login(dto : UserRequestDTO) : UserResponse
suspend fun register(dto : UserRequestDTO) : UserResponse
suspend fun findID(dto : UserRequestDTO) : UserResponse
suspend fun findPW(dto : UserRequestDTO) : UserResponse
}
private class UserRepositoryImpl: UserRepository {
@Inject
private lateinit var backend : UserService
override suspend fun login(dto: UserRequestDTO): UserResponse {
return withContext(Dispatchers.IO){
//처리코드
}
UserResponse.Login(responseDTO)
}
}
override suspend fun register(dto: UserRequestDTO): UserResponse {
return withContext(Dispatchers.IO) {
//처리코드
UserResponse.Register(responseDTO)
}
}
override suspend fun findID(dto: UserRequestDTO): UserResponse {
return withContext(Dispatchers.IO){
//처리코드
UserResponse.FindIdPw(responseDTO)
}
}
override suspend fun findPW(dto: UserRequestDTO): UserResponse {
return withContext(Dispatchers.IO){
//처리코드
UserResponse.FindIdPw(responseDTO)
}
}
class LoginViewModel : ViewModel() {
private val _loginResult = MutableLiveData<LoginResult>() //로그인
val loginResult: LiveData<LoginResult> = _loginResult
private val _registerResult = MutableLiveData<LoginResult>() //회원가입
val registerResult: LiveData<LoginResult> = _registerResult
private val _findIDinResult = MutableLiveData<LoginResult>()
val findIDinResult: LiveData<LoginResult> = _findIDinResult //ID찾기
private val _findPWResult = MutableLiveData<LoginResult>()
val findPWResult: LiveData<LoginResult> = _findPWResult //PW찾기
fun requestFindID(){
if(TODO("아이디찾기")){
_findIDinResult.value = LoginResult(true)
} else {
_findIDinResult.value = LoginResult(false)
}
}
fun requestFindPW(){
if(TODO("비밀번호찾기")){
_findPWResult.value = LoginResult(true)
} else {
_findPWResult.value = LoginResult(false)
}
}
fun requestCheckNickname(nickname: String){
if(TODO("회원가입")){
_registerResult.value = LoginResult(true)
} else {
_registerResult.value = LoginResult(false)
}
}
fun requestRegister(request : RegisterRequest){
if(TODO("회원가입")){
_registerResult.value = LoginResult(true)
} else {
_registerResult.value = LoginResult(false)
}
}
fun login(username: String, password: String, autoLogin : Boolean = false) {
if (isUserNameValid(username) && isPasswordValid(password)) {
//로그인 검증 과정생략
_loginResult.value = LoginResult(true)
} else {
_loginResult.value = LoginResult(false)
}
}
}
LoginActivity에서 사용하는 LoginViewModel에서
1. 로그인
2. 회원가입
3. 아이디 찾기
4. 비밀번호 찾기
4가지 요청에 대해 서버에서 검증 결과를 받아와야 하는데
Observer 패턴을 사용하여 결과값이 넘어오는 과정을 보기 위해서 총 4개의 LiveData를 제작했었다.
연관된 행동(하나의 액티비티에서 들어온 요청에 대한 검증)이 각각 따로 적혀 있어 난잡해 보인다.
class LoginViewModel : ViewModel() {
private val repository = UserRepository()
val _response = MutableLiveData<LoginResponse>()
val response : LiveData<LoginResponse> = _response
val request : (LoginRequest) -> Unit
init {
request = { requestType ->
val dto = requestType.dto
viewModelScope.launch {
when(requestType){
//로그인
is LoginRequest.Login -> {
if ((isUserNameValid(requestType.dto.email) && isPasswordValid(requestType.dto.password))) {
_response.value = LoginResponse.Login(repository.login(dto))
}
}
//회원가입
is LoginRequest.Register -> {
_response.value = LoginResponse.Register( repository.register(dto))
}
//아이디찾기
is LoginRequest.FindPW -> {
_response.value = LoginResponse.FindIdPw(repository.findID(dto))
};
//비밀번호찾기
is LoginRequest.FindID -> {
_response.value = LoginResponse.FindIdPw( repository.findPW(dto) )
};
}
}
}
}
}
sealed class LoginRequest() {
abstract val dto: UserRequestDTO
data class Login(override val dto : LoginRequestDTO) : LoginRequest()
data class FindPW(override val dto : FindPwRequestDTO) : LoginRequest()
data class FindID(override val dto : FindIdRequestDTO) : LoginRequest()
data class Register(override val dto : RegisterRequestDTO) : LoginRequest()
}
sealed class LoginResponse{
abstract val dto : UserResponseDTO
data class Login(override val dto : LoginResponseDTO) : LoginResponse()
data class FindIdPw(override val dto : FindResponseDTO) : LoginResponse()
data class Register(override val dto : SuccessResponse) : LoginResponse()
우선 Activity에서 요구할 수 있는 Request들을 각각 Data Class로 생성하여 LoginRequest로 묶어줬다.
request와 response의 종류가 sealed class로 묶여져 있어 한눈에 파악이 가능했으며,
어떤 요청을 수행하든 결과를 response 라이브 데이터에 LoginResponse 클래스로 넣게 되면, 해당 값을 Observe하는 Activity Component에서 해당 결과에 대한 타입을 구분하여 UI에 반영해 줄 수 있었다.
추가적으로 각각의 요구에 대해 Repository 단에서 필요로 하는 양식들을 UserResponseDTO, UserRequestDTO로 묶어 선언해 줌으로써 OCP 개념을 준수하기 위해 노력했다.
예를 들어 추가적인 '이름검색'과 같은 요청이 필요하다 싶으면 , UserRequestDTO와 LoginRequest에만 해당 항목을 추가하면 되므로 기존에 구현된 항목에 대한 수정을 불필요하게 된다.
결국 핵심은 바뀌는 리스트를 넘겨주는 것이 나타내고 싶은 상태가 고정된 리스트 (toList로 새 리스트에 복사)로 전달하는 것이 핵심이다.
submitList(itemList.toList())
추가적으로 LiveData를 다루는 데 있어
단순 _capturedImages.value!!.add(image)와 같이 MutableLiveData의 value인 ArrayList에 add/remove를 통해 수정/삭제하여 옵저버 패턴이 반응하기를 기대했었는데 value 자체가 바뀐 것이 아니라 반응하지 않는 것을 확인했다.
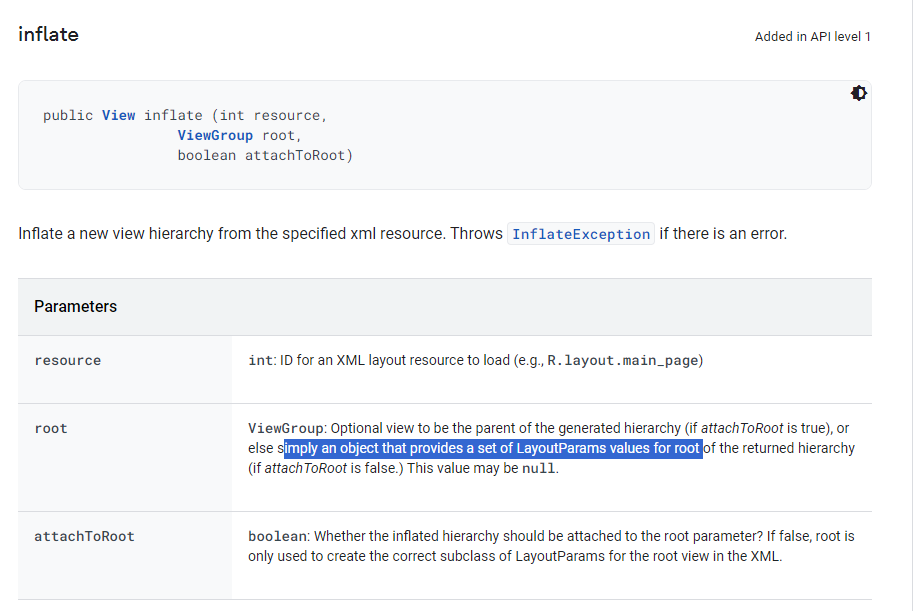
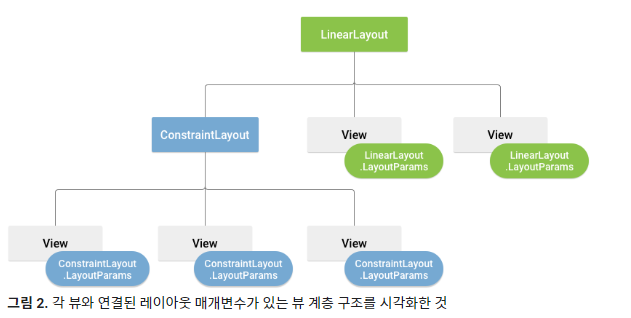
를 사용할 시 root의 LayoutParams가 제공되기에 앞선 예제2 코드와 같이 짤 필요는 없다.
추가적으로, attachRoot의 경우 true를 하면 inflate와 동시에 parent의 계층 구조에 속하게 되므로, viewholder에는 적합하지 않다. ( 해당 링크의 예시 코드를 보면 inflate 후 addView를 하여 뷰를 추가하는 것이 확인가능하며, attachRoot = ture인 경우 addView가 필요없음을 확인가능하다. )
On Android, it's essential to avoid blocking the main thread. The main thread is a single thread that handles all updates to the UI. It's also the thread that calls all click handlers and other UI callbacks. As such, it has to run smoothly to guarantee a great user experience. For your app to display to the user without any visible pauses, the main thread has to update the screen roughly every 16ms, which is about 60 frames per second. Many common tasks take longer than this, such as parsing large JSON datasets, writing data to a database, or fetching data from the network. Therefore, calling code like this from the main thread can cause the app to pause, stutter, or even freeze. And if you block the main thread for too long, the app may even crash and present an Application Not Responding dialog.
→메인 쓰레드는 UI 업데이트를 총괄하는 하나의 쓰레드로, 시간이 소요가 클 것으로 예상되는 일반적인 작업들이 메인 쓰레드를 차단하지 않도록 하는것이 필수적
기능
경량 (Light-weight): 코루틴을 실행 중인 스레드를 차단하지 않는정지(suspension) 를 지원하므로, 단일 스레드에서 많은 코루틴을 실행할 수 있습니다.
메모리 누수 감소 : 구조화된 동시 실행(structured concurrency )을 사용하여 범위(scope) 내에서 작업합니다.
기본으로 제공되는 취소(Cancelation) 기능 : 실행 중인 코루틴 계층 구조를 통해 자동으로 취소(Cancelation)이 전달됩니다.
Jetpack 통합: 많은 Jetpack 라이브러리에 코루틴을 완전히 지원하는 확장 프로그램 포함. 일부 라이브러리에서 구조화된 동시 실행에 사용할 수 있는 코루틴 스코프도 지원
Process :보조기억장치의 '프로그램'이 메모리 상으로 적재되어 실행되면 '프로세스'가 된다. '힙'을 할당 받음 Thread : Process 하위에 종속되는 보다 작은 단위로, 작업의 단위. 각 쓰레드는 독립된 메모리 영역인 스택(Stack)을 갖는다. Coroutine : 작업의 단위가 되는 객체. JVM Heap 에 적재되어 (코틀린 기준) 프로그래머의 코드에 의해 Context Switching 없이 동시성 보장
경량
→ 쓰레드는 병렬성(Parallelism)을 만족하는 것이 아니라 동시성(Concurrency)을 만족
→ 동시성 만족을 위해 OS 커널에 의한 Context Switching (시분할기법)
→ 코루틴은 동시성 만족을 위해 프로그래머에 의해 스케줄링
총체적으로 봤을 때 커널 입장에서 Preempting Scheduling (선점형 스케줄링) 을 통하여 각 태스크를 얼만큼 수행할지, 혹은 무엇을 먼저 수행할지를 결정하여 알맞게 동시성을 보장하게 되는 것이다.
작업의 단위를 Object 로 축소하면서 하나의 Thread 가 다수의 코루틴을 다룰 수 있기 때문에, 작업 하나하나에 Thread 를 할당하며 메모리 낭비, Context Switching 비용 낭비를 할 필요가 없음같은 프로세스 내의 Heap 에 대한 Locking 걱정 또한 사라짐
sealed class Result<out R> {
data class Success<out T>(val data: T) : Result<T>()
data class Error(val exception: Exception) : Result<Nothing>()
}
class LoginRepository(private val responseParser: LoginResponseParser) {
private const val loginUrl = "https://example.com/login"
// Function that makes the network request, blocking the current thread
fun makeLoginRequest(
jsonBody: String
): Result<LoginResponse> {
val url = URL(loginUrl)
(url.openConnection() as? HttpURLConnection)?.run {
requestMethod = "POST"
setRequestProperty("Content-Type", "application/json; utf-8")
setRequestProperty("Accept", "application/json")
doOutput = true
outputStream.write(jsonBody.toByteArray())
return Result.Success(responseParser.parse(inputStream))
}
return Result.Error(Exception("Cannot open HttpURLConnection"))
}
}
→ 이 코드에서 주요하게 봐야할 점은 LoginResponse를 받아오기 위한 makeLoginRequest 가 동기식으로, 호출 스레드를 차단한다는 점이다.
동기식
class LoginViewModel(
private val loginRepository: LoginRepository
): ViewModel() {
fun login(username: String, token: String) {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
loginRepository.makeLoginRequest(jsonBody)
}
}
→ UI 스레드가 차단됨 →OS는onDraw()를 호출할 수 없으므로 앱이 정지되고 애플리케이션 응답 없음(ANR) 대화상자가 표시될 수 있습니다.
비동기식
class LoginViewModel(
private val loginRepository: LoginRepository
): ViewModel() {
fun login(username: String, token: String) {
// Create a new coroutine to move the execution off the UI thread
viewModelScope.launch(Dispatchers.IO) {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
loginRepository.makeLoginRequest(jsonBody)
}
}
}
viewModelScope는 ViewModel KTX 확장 프로그램에 포함된 사전 정의된 CoroutineScope입니다. 모든 코루틴은 범위 내에서 실행해야 합니다. CoroutineScope는 하나 이상의 관련 코루틴을 관리합니다.
launch는 코루틴을 만들고 함수 본문의 실행을 해당하는 디스패처에 전달하는 함수입니다.
Dispatchers.IO는 이 코루틴을 I/O 작업용으로 예약된 스레드에서 실행해야 함을 나타냅니다.
Login함수의 실행 순서
앱이 기본 스레드의 View 레이어에서 login 함수를 호출합니다.
launch가 새 코루틴을 만들며, I/O 작업용으로 예약된 스레드에서 독립적으로 네트워크 요청이 이루어집니다.
코루틴이 실행되는 동안 네트워크 요청이 완료되기 전에 login 함수가 계속 실행되어 결과를 반환합니다. 편의를 위해 지금은 네트워크 응답이 무시됩니다.
이 코루틴은 viewModelScope로 시작되므로 ViewModel 범위에서 실행됩니다. 사용자가 화면 밖으로 이동하는 것으로 인해 ViewModel이 소멸되는 경우 viewModelScope가 자동으로 취소되고 실행 중인 모든 코루틴도 취소됩니다.
기본 안전(Main-Safety)을 위한 코루틴 사용
기본 안전(Main-Safety) : 기본 스레드에서 UI 업데이트를 차단하지 않는 함수
앞서 나온 makeLoginRequest는를 비동기식으로 안전하게 사용하기 위해서는, 호출하는 모든 항목이 명시적으로 실행을 기본 스레드 외부로 이동해야 합니다. (viewModelScope.launch(Dispatchers.IO))
Repository
class LoginRepository(...) {
...
suspend fun makeLoginRequest(
jsonBody: String
): Result<LoginResponse> {
// Move the execution of the coroutine to the I/O dispatcher
return withContext(Dispatchers.IO) {
// Blocking network request code
}
}
}
→ suspend 키워드를 통해 Coroutine 내에서 함수가 호출되도록 강제합니다.
→ withContext(Dispatchers.IO)는 코루틴 실행을 I/O 스레드로 이동하여 호출 함수를 기본 안전 함수로 만들고 필요에 따라 UI를 업데이트하도록 설정합니다.
☞ Coroutine 내에서 makeLoginRequest함수 호출을 강제하고, 함수가 호출되면 withContext(Dispatchers.IO)를 통해 I/O 스레드로 이동하여 실행합니다.
ViewModel
class LoginViewModel(
private val loginRepository: LoginRepository
): ViewModel() {
fun makeLoginRequest(username: String, token: String) {
viewModelScope.launch {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
val result = try {
loginRepository.makeLoginRequest(jsonBody)
} catch(e: Exception) {
Result.Error(Exception("Network request failed"))
}
when (result) {
is Result.Success<LoginResponse> -> // Happy path
else -> // Show error in UI
}
}
}
}
makeLoginRequest가suspend함수이므로 코루틴은 여전히 필요하며, 모든suspend함수는 코루틴에서 실행되어야 합니다.
launch가Dispatchers.IO매개변수를 사용하지 않아viewModelScope에서 실행된 코루틴이 기본 스레드(UI Thread)에서 실행됩니다.
네트워크 요청의 결과가 이제 성공 또는 실패 UI를 표시하도록 처리됩니다.
이제 로그인 함수가 다음과 같이 실행됩니다.
앱이 기본 스레드의View레이어에서login()함수를 호출합니다.
launch가 기본 스레드에 새 코루틴을 만들고 코루틴이 실행을 시작합니다.
코루틴 내에서 이제loginRepository.makeLoginRequest()호출은makeLoginRequest()의withContext블록 실행이 끝날 때까지 코루틴의 추가 실행을정지합니다.
withContext블록이 완료되면login()의 코루틴이 네트워크 요청의 결과와 함께기본 스레드에서 실행을 재개합니다.
마무리
1. UI 업데이트를 총괄하는 메인 쓰레드가 차단되는 것을 방지하는 것이 필수적으로 요청에 대한 결과가 바로 이어지지 않는 경우 비동기식 프로그래밍이 필요
2. Coroutine은 Context Switching 없이 코드를 통해 동시성을 보장가능하게 해주는 객체 (비동기적 실행을 위한 동시 실행 설계 패턴)
3. 기본안전을 위해 Coroutine 사용을 강제하는 suspend 키워드 권장(Main-Safety)